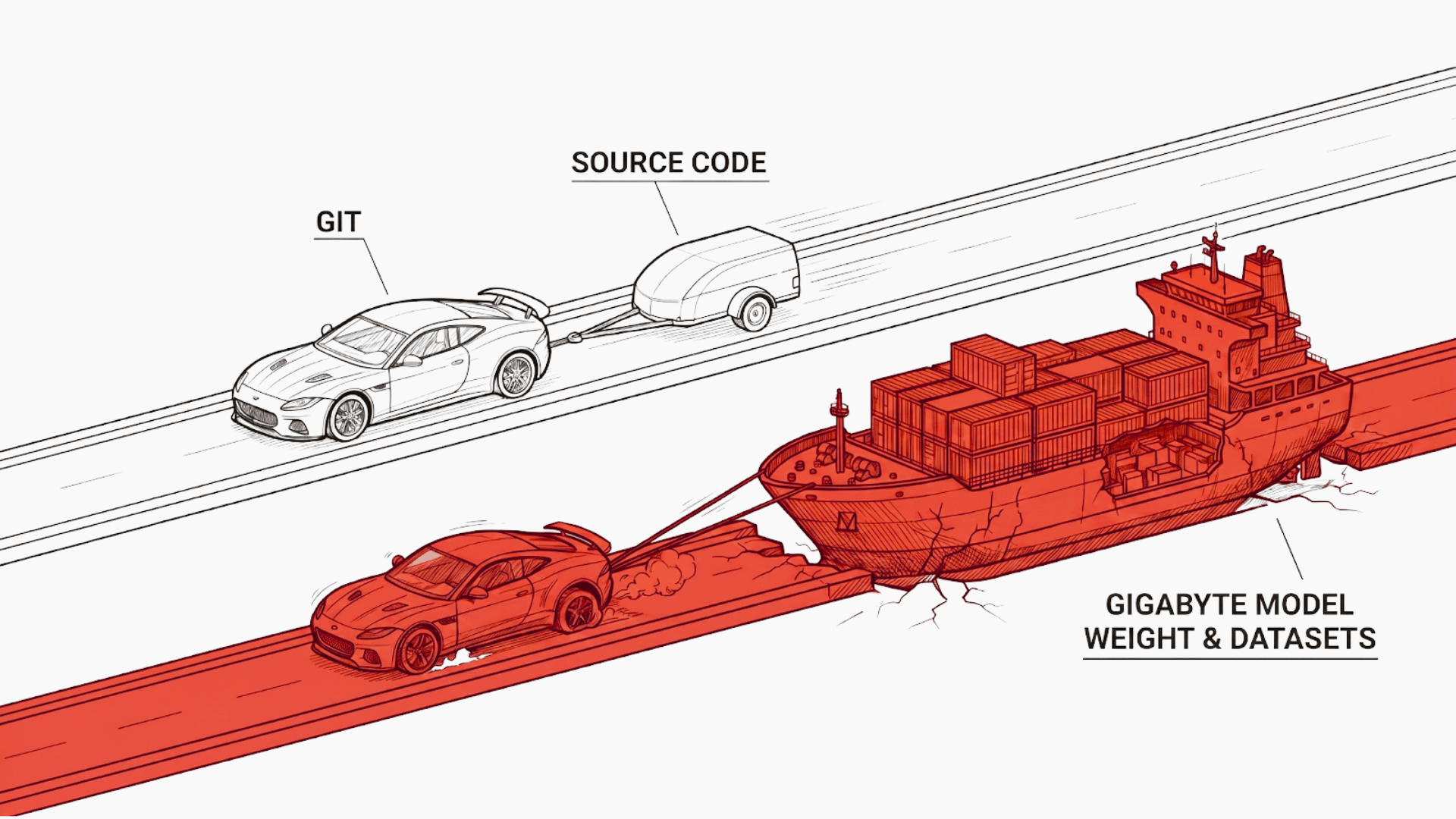

At Zentara, we are constantly pushing the boundaries of connectivity and infrastructure. As we scale our AI initiatives, one question consistently surfaces among our engineering teams: “How do we version these massive LLM models without breaking our development workflow?”. Managing source code is a solved problem. Git is the gold standard. But when you introduce a 15GB model checkpoint or a 50GB training dataset into a standard Git repository, the tools we rely on every day start to choke.
Git is optimized for text. It handles line-by-line diffs and compresses changes beautifully. However, machine learning is a different beast. LLM weights are dense binary blobs. At our scale, committing these files directly to Git creates a “Gravity Well.” Every time a weights file is updated, Git attempts to store a full copy of that binary because it cannot compute a meaningful text-based delta. A repository with just ten iterations of a large model can easily swell to hundreds of gigabytes. This leads to agonizingly slow clones, timed-out pushes, and local storage exhaustion. The core technical issue is how Git handles history. When you modify a Python script, Git stores only the changed lines. When you modify a .bin or .safetensors model file, Git sees a completely new file.
- Bloat: Your .git folder grows linearly with every “save.”
- Performance: Commands like git status begin to lag as they hash gigabytes of data.
- Collaboration: Distributed teams cannot effectively sync when the “entry price” for joining a repo is a multi-hour download.
To maintain engineering excellence, we must decouple the versioning logic from the physical storage. We compared three primary solutions to see which best fits the Zentara ecosystem.
1. Git LFS (Large File Storage)
Git LFS replaces the large file in your repository with a tiny text “pointer” file. This pointer contains a SHA-256 hash of the actual file. The physical data is stored on a separate LFS server (like GitHub’s or our internal storage).
Implementation Flow:
- Initialize LFS: git lfs install.
- Track specific extensions: git lfs track “*.safetensors”.
- The .gitattributes file is updated to route these binaries through the LFS filter.
It keeps the repository lightweight. Developers only download the specific version of the model they are currently checking out. This is exactly why we use it at Zentara because it integrates seamlessly with our existing Git-based CI/CD pipelines.
2. DVC (Data Version Control)
DVC is often called “Git for Data.” It doesn’t just store files but rather versions of the entire ML lifecycle. Like LFS, it uses metafiles (e.g., model.pkl.dvc) as placeholders. DVC shines because it is pipeline-aware. In a DVC workflow, you define a dvc.yaml file that maps dependencies.
- First Step: Define the stage: dvc run -n train -d data/raw -o model.bin python train.py.
- Second Step: DVC tracks the exact hash of the input data and the resulting model.
If the input data doesn’t change, DVC skips the re-computation. Isn’t that a beautiful way to save GPU hours?
3. XET (Now part of Hugging Face)
XET takes a more granular approach using Content-Defined Chunking (CDC). Instead of tracking files, it breaks them into ~64KB chunks. If you tweak a small piece of metadata or a few layers in a GGUF model, LFS and DVC would re-upload the entire file. XET identifies that 99% of the chunks are identical and only sends the diff.
- Result: Up to 10x faster transfers for iterative model updates.
- Visual Language: Imagine a Merkle Tree where only the red leaves (changed data) are pushed to S3, while the rest are referenced from the existing Content Addressed Store (CAS).
Comparison Matrix
| Feature | Git LFS | DVC | XET |
| Primary Use | General Large Assets | ML Reproducibility | Massive Model Iteration |
| Deduplication | File-level | File-level | Block/Chunk-level |
| Complexity | Low (Invisible) | Medium (New CLI) | Medium (Mountable VFS) |
| Best For | Stable workstreams | Pipeline-heavy teams | Rapid model fine-tuning |
By standardizing on Git LFS, we’ve ensured that our primary repositories remain under 1GB of source code, regardless of how many models we train. This allows a new engineer to clone our core connectivity stack and be ready to code in under 60 seconds, rather than waiting for a 20GB binary dump. The choice of tool ultimately depends on your team’s specific pain point. If you need reproducibility DVC is your friend. If you are doing massive, iterative fine-tuning of TB-scale datasets, XET’s chunking is a game-changer. For us, the simplicity of LFS allows us to stay focused on our core mission.


