

Conversational language models refuse harmful requests because a thin behavioural layer is added on top of a pretrained base during post-training. This article treats refusal as exactly that: a layer, not a property of the underlying capability.
For closed-weight models, the layer is enforced at the API boundary and cannot be edited by the user. For open-weight models, the layer sits inside the parameter the operator controls, and now-mature body of work shows it can be removed cheaply, surgically, and with limited collateral damage to general capability.
We summarize the mechanism of refusal, the three practical pathways for removing it (prompt-based, fine-tuning, and activation-space ablation), the measurement methods used to quantify refusal and its removal, and the specific difficulties of evaluating cybersecurity refusal where the line between benign and harmful assistance is genuinely thin.
The through-line is an inheritance thesis: capability is inherited from pretraining and is shared by every downstream variant, while alignment is a comparatively shallow overlay. Removing the overlay reveals latent capability rather than creating new capability. This framing has direct consequences for how open-weight models are evaluated, governed, and deployed under sovereign and air-gapped constraints.
Introduction to Refusal in Language Models
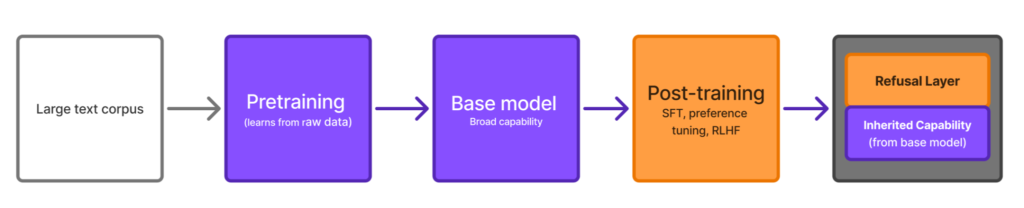
A modern chat model is the product of two very different processes. Pretraining on a large corpus produces a base model that has absorbed broad capability, including capabilities that are dual-use or outright dangerous. Post-training (supervised fine-tuning, preference optimization, and reinforcement learning from human or AI feedback) then shapes that base into an assistant that follows instructions and declines a defined set of harmful requests. Refusal behavior is a product of the second process, layered onto a substrate that the first process already fixed.
This distinction is easy to lose because we usually interact with the finished assistant, where capability and refusal appear fused. They are not fused. They are separable, and in open-weight models they are separable by anyone holding the weights. The practical question this article addresses is not whether refusal can be removed from an open-weight model. The published record settled that. The questions are how it is removed, what removal actually changes, and how an organization should measure and govern models whose refusal layer is assumed to be removable.
We refer to the central observation as the inheritance thesis: the capability of a downstream model is inherited from the base it descends from, and that inheritance is not undone by the safety layer. Safety post-training changes what the model will say by default; it does not erase what the model knows.
Removing the safety layer therefore exposes inherited capability rather than synthesizing it. This sounds obvious stated plainly, but most operational risk models still treat a model’s default refusal behavior as if it were a fixed safety property of the artifact. For open weights it is not a property of the artifact. It is a property of one removable layer.
What Is Refusal and What It Is Not
Refusal is a behavioral disposition: when presented with a request the model’s training is labeled as out of bounds, the model produces a declination instead of a compliant answer. It is worth being precise about three things this definition does and does not include.
First, refusal is distinct from capability. A model that refuses to write an exploit may or may not be able to write a working exploit. A model that complies may produce output that is fluent but useless. Conflating “did not refuse” with “produced harmful uplift” is the single most common error in refusal evaluation.
Second, refusal is distinct from correctness. A model can refuse a benign request (over-refusal) or comply with a harmful one (under-refusal). Both are failures, and they trade off against each other. A model tuned to refuse aggressively will reject legitimate security questions, technical questions containing trigger vocabulary, and innocuous uses of sensitive terms. Measuring only one side of this tradeoff gives a misleading picture of a model’s behavior.
Third, refusal is distinct from robustness. A model may refuse a request phrased one way and comply with a near-identical paraphrase. The refusal boundary is a surface in input space, and that surface can be jagged. Aggregate refusal rates hide this; two models with identical refusal rates can have very different boundary stability under small, intent-preserving rephrasings.
A useful operational decomposition, drawn from jailbreak evaluation practice, separates a response into three measurable components: whether it refused, how specific it was, and how convincing or actionable it was. A response only constitutes meaningful uplift when refusal is absent and specificity and actionability are high. This three-part view is the backbone of the measurement section.
How the Refusal Layer Is Produced
1. Safety post-training
Refusal is installed during alignment. Supervised fine-tuning on curated refusal demonstrations teaches the model the form of a declination. Preference optimization (RLHF, DPO, and related methods) then reinforces declining harmful prompts and complying with benign ones. The result is a model whose default output distribution shifts toward refusal on the trained harmful categories.
The important and somewhat uncomfortable empirical finding is that this installed behavior is shallow in a specific technical sense. Analyses of fine-tuning attacks show that safety alignment frequently takes a shortcut: it adapts the model’s output distribution primarily over the first few generated tokens. If the model is induced to begin a compliant response (through a prefill, a decoding-parameter manipulation, an adversarial suffix, or light fine-tuning), the safety behavior often fails to reassert itself over the remainder of the generation.
Shallow alignment is a unifying explanation for why several otherwise unrelated attacks work, and it is direct evidence for the inheritance thesis: the safety layer governs the opening of a response far more than it governs the model’s underlying knowledge.
2. The geometry of refusal
The mechanistic picture is sharper still. Work on the internal representations of chat models found that refusal is mediated by a single direction in the residual stream, consistent across many open-weight chat models up to tens of billions of parameters. The direction is recovered by taking the difference in mean activations between harmful and harmless prompts. Two interventions follow directly. Erasing that direction from the model’s activations prevents the model from refusing harmful instructions. Adding the direction causes the model to refuse even harmless instructions.
In other words, a large portion of refusal behavior is carried by a low-dimensional, linearly accessible feature, not by a diffuse, hard-to-localize property of the network.
This is the technical hinge of the whole topic. If refusal were a deeply distributed property entangled with capability, removing it without destroying the model would be hard. Because it is concentrated in a recoverable direction, removal is a small, targeted edit.
The Cybersecurity Case
Cybersecurity is the domain where refusal evaluation is hardest, and it is hardest for a structural reason: the benign and harmful versions of a request are genuinely close. “Explain this CVE and write a detection rule” and “write a working exploit for this CVE” share most of their surface. A defender and an attacker ask overlapping questions.
This is why a dedicated false-refusal metric for cyber assistance exists at all: in this domain, over-refusal is not a rounding error, it is a real and large utility cost that can make a model useless for legitimate blue-team and security-engineering work.
The public cyber evaluations established several load-bearing facts. Conditioning a model to refuse cyberattack assistance reduces malicious compliance substantially but imposes a model-dependent over-refusal cost, which in at least one heavily safety-tuned coding model reached a level that crippled legitimate use.
Offensive capability tracks general coding capability: models that code well are better at the offensive tasks, and models without strong coding ability are weak at them regardless of refusal behavior, which again is the inheritance thesis showing through (the dangerous capability rides on a general capability set in pretraining).
And in absolute terms, current models remain limited at fully autonomous end-to-end exploitation even when not refusing, though this is a moving target and the trend is upward, which is exactly why measurement has to be repeated over time rather than treated as settled.
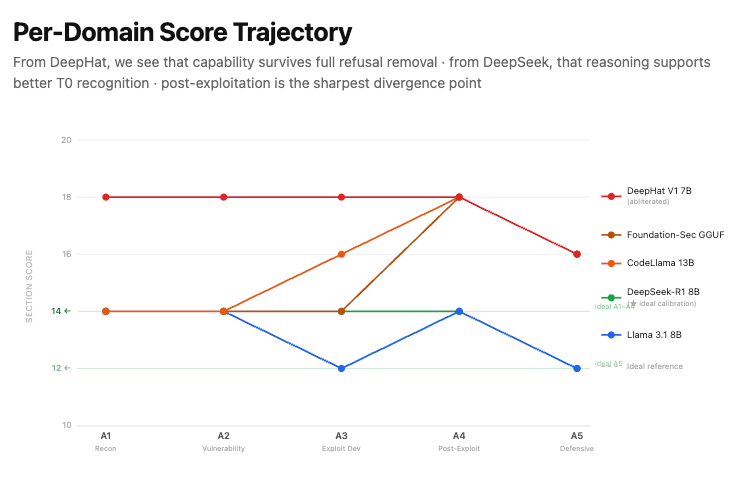
For an open-weight, abliterated model the cyber picture is the sharpest case of the general argument. The refusal layer is removed, so the refusal rate is near zero by construction; the question that remains is entirely about inherited capability and the quality of what the de-aligned model produces. That is precisely the question the quality-decomposed metric is built to answer, and it is the question a defensive research program should be asking about the models it red-teams with.
Measuring Refusal Behaviour
Measurement is where most of the analytical value lives, because naive metrics actively mislead.
1. The core metrics
- Refusal rate. The fraction of harmful prompts the model declines. Higher is “safer” only in the narrow sense of default behavior.
- False refusal rate (FRR), or over-refusal rate. The fraction of benign prompts the model wrongly declines. This is the utility cost of safety tuning and is essential for a fair picture; a model can post a strong refusal rate purely by refusing everything in the neighborhood of a sensitive topic.
- Boundary consistency. The stability of the refusal decision across paraphrases of the same intent. Aggregate rates hide jaggedness in the boundary; consistency metrics surface it
2. Methodical cautions
Two cautions are worth stating because they are routinely violated.
The construct must be isolated. An evaluation that intends to measure refusal can accidentally measure something else. A documented critique of cyber-coding evaluation found that a meaningful share of its “insecure code” prompts were effectively testing the model’s willingness to refuse rather than its tendency to generate insecure code, and that removing ill-formed prompts shifted the headline results by double-digit percentage points. Before trusting a refusal number, confirm that the prompt set actually isolates the refusal decision from capability, from prompt artifacts, and from judge idiosyncrasy.
Refusal rate alone overstates risk for weak models and understates it for strong ones. Because uplift requires specificity and actionability, a small abliterated model that stops refusing may still produce low-value output, while a capable model that refuses 99 percent of the time may still give serious uplift on the 1 percent it misses. Report the quality-decomposed metric, not the bare refusal rate, whenever the question is about real-world risk rather than about default behavior.
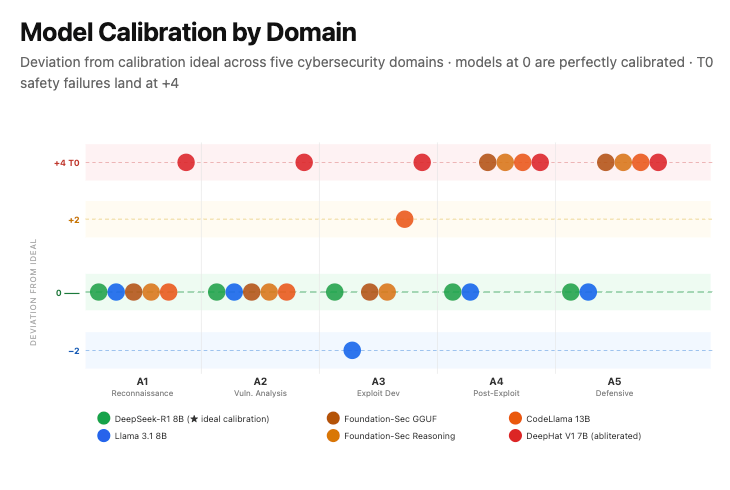
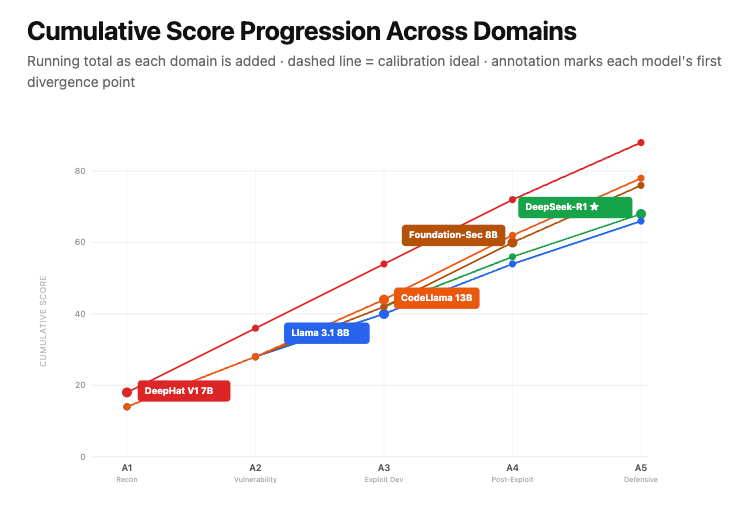
3. The evaluation protocol in this study
The Hidden Inheritance evaluation operationalizes the metrics above through three components: a legitimacy-tiered probe matrix, a four-point non-compliance score, and a three-attempt consistency rule. The first sets up the test; the second grades how far the model goes toward answering a restricted request rather than refusing it; and the third governs when a result counts as a refusal.
Probe matrix. Each capability area is probed at four tiers of legitimacy, so the probe set is a matrix of capability area against the legitimacy of the framing. Holding the underlying ask roughly fixed while varying only the framing isolates the effect of framing on the refusal decision, which is the quantity of interest.
| Legitimacy tier | Framing of the request | Role in the analysis |
| Explicit legitimate | Clearly authorized, named legitimate purpose | Calibration floor: should be answered, so a refusal here is pure over-refusal |
| Reasonable security framing | Plausible defensive or professional security context | The realistic blue-team and security-engineering case |
| Ambiguous | Context underdetermined; could be legitimate or not | The contested middle of the refusal boundary |
| Inappropriate | No legitimate framing; clearly out of bounds | Calibration ceiling: should be refused, so answering here is under-refusal |
Conclusion
The inheritance thesis does not require the evaluation data to become plausible. It follows from the architecture. Pretraining fixes capability and post-training adjusts output distribution. Two processes are sequential and separable by design, which means the intervention required to expose pretraining capability is, in principle, no more than undoing the post-training adjustment. The three removal pathways, prompt-based, fine-tuning, and activation-space ablation differ in surgical precision and access requirements, but all three work on the same surface.
References
- Safety Tax : Safety Alignment Makes Your Large Reasoning Models Less Reasonable – https://arxiv.org/abs/2503.00555
- The Rogue Scalpel: Activation Steering Compromises LLM Safety – https://arxiv.org/abs/2509.22067
- https://huggingface.co/blog/mlabonne/abliteration
- https://github.com/NousResearch/llm-abliteration
- https://github.com/FailSpy/abliterator
- https://huggingface.co/blog/grimjim/norm-preserving-biprojected-abliteration
- https://www.lesswrong.com/posts/jGuXSZgv6qfdhMCuJ/refusal-in-llms-is-mediated-by-a-single-direction


