

Underground forums, dark web marketplaces, and encrypted chat channels generate millions of posts daily, previous research shows only about 20% of that content is actually relevant to Cyber Threat Intelligence (CTI). Zentara Labs research a multi-engine topic modeling pipeline that applies LDA, BERTopic, Top2Vec, and an LLM interpretation layer (TopicGPT) to automatically cluster noisy CTI data into actionable threat topics.
In a comparable large-scale study analyzing 6.6 million posts, 3.4 million chat messages, and 120,000 darknet websites, BERTopic with a domain-tuned embedding model (ATT&CK BERT) identified 83 distinct topics, with the dominant threat clusters including Account & Subscription Selling, Carding, Data Leaks, Hacking, DDoS/Proxies, and Scam operations.
This approach reduces analyst review volume by up to 80%, letting CTI and SOC teams focus on the signals that matter emerging threats, platform comparisons, and threat hunting hypotheses.
Pipeline Design: From Noisy CTI Data to Actionable Threat Topics
Rather than evaluating topic modeling algorithms in isolation, we designed a production-oriented pipeline that connects data sources, preprocessing, embedding, topic modeling, and LLM-based interpretation into one end-to-end system.
The central question this pipeline answers is: how do we turn millions of noisy dark web and underground forum messages into a small, prioritized set of threat topics that CTI and SOC teams can actually act on?
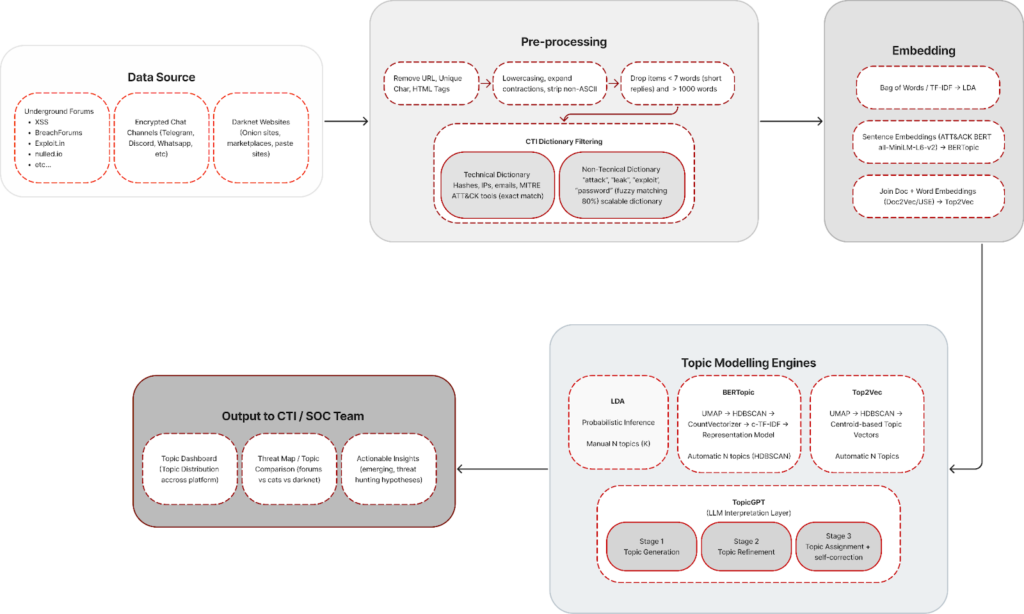
The pipeline operates in four main stages:
1. Collection from Data Sources & CTI Dictionary Filtering with Pre-processing
Data is collected from underground forums, encrypted chat channels, and darknet sites. A dual-dictionary approach is applied: exact matching for technical artifacts (hashes, IPs, emails, MITRE ATT&CK tools) and fuzzy matching (~80% threshold) for threat-related terms (“attack,” “leak,” “exploit,” “password”). This step removes most noise, leaving roughly 20% CTI-relevant content.
2. Embedding Strategy (Model Selection Stage)
Filtered CTI data is transformed into vector representations depending on the modeling strategy selected.
Because each topic modeling algorithm requires a different representation space, the embedding step is aligned with the chosen engine:
- TF-IDF / Bag-of-Words → used when applying LDA
- Sentence embeddings (ATT&CK BERT / MiniLM) → used for BERTopic
- Doc2Vec / Universal Sentence Encoder → used for Top2Vec
3. Topic Modeling Execution
Each engine is then executed independently on the same filtered dataset:
- LDA → Bayesian inference with manually defined topic count
- BERTopic → UMAP → HDBSCAN → c-TF-IDF with automatic topic discovery
- Top2Vec → Embedding-space clustering with automatic topic generation
At this stage, we obtain candidate threat topics from three different modeling paradigms:
- Probabilistic (LDA)
- Transformer + density clustering (BERTopic)
- Semantic embedding clustering (Top2Vec)
4. LLM Interpretation Layer (TopicGPT-style)
An LLM reads cluster samples to generate human-readable topic labels, merge redundant clusters, produce concise descriptions, and extract representative quotes. This transforms raw clusters into analyst-ready intelligence.
Why the pipeline matters more than any single algorithm
In practice, the pipeline architecture defines how raw CTI data becomes repeatable, explainable input for detection engineering and threat hunting. Any individual method can be swapped or upgraded without disrupting the overall system.
However, after filtering and representation, the system still produces a large volume of unstructured text that cannot be directly analyzed by analysts. A mechanism is therefore required to automatically organize this data into meaningful threat categories. This role is fulfilled by topic modeling.
What Is Topic Modeling?
Topic modeling is an unsupervised technique for discovering “hidden themes” in a collection of documents. In practical terms, if you have 10,000 unlabeled emails, topic modeling automatically groups them into categories (bills, personal letters, spam, etc.) without you having to create manual rules.
In the context of CTI and OSINT, this technique can automatically categorize forum posts, chat messages, and dark web content into topics such as carding, DDoS-as-a-service, credential stuffing, ransomware distribution, and account selling.
Topic modeling can be categorized into four major groups: algebraic, probabilistic, neural, and LLM (Large Language Model)-based. This blog will discuss LDA, BERTopic, Top2Vec, and TopicGPT.
1. LDA (Latent Dirichlet Allocation) as a Probabilistic Method
LDA is the most popular generative probabilistic topic modeling method and has been the standard since its introduction by Blei, Ng, and Jordan in 2003. LDA assumes that each document is a mixture of several topics, and each topic is a probability distribution over words.
How LDA works
LDA uses a two-step generative process
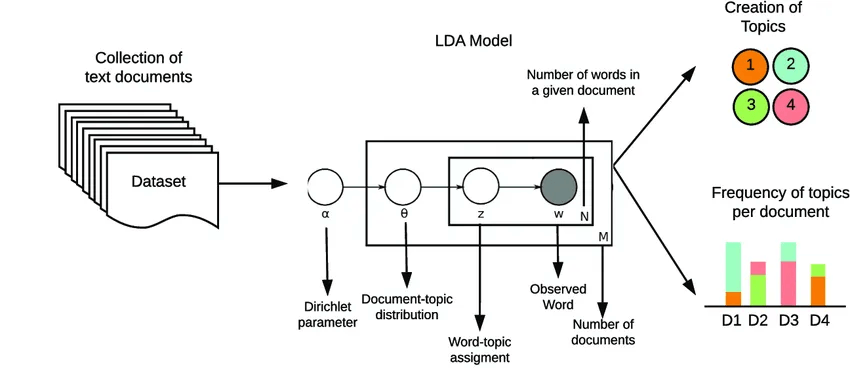
- For each document/sentence, the topic distribution is taken from the Dirichlet prior (parameter α).
- For each word in the document, one topic is selected from the distribution, then a word is selected from the distribution of words for that topic (parameter β).
The LDA inference technique uses Bayesian inference to “reverse engineer” hidden topics from the words observed in the document.
2. BERTopic as a Neural (Embedding-based) Method
BERTopic is a modern topic modeling technique developed by Maarten Grootendorst. BERTopic works by utilizing the power of transformer embeddings and class-based TF-IDF (c-TF-IDF) to produce dense and easily interpretable topics.
How BERTopic works
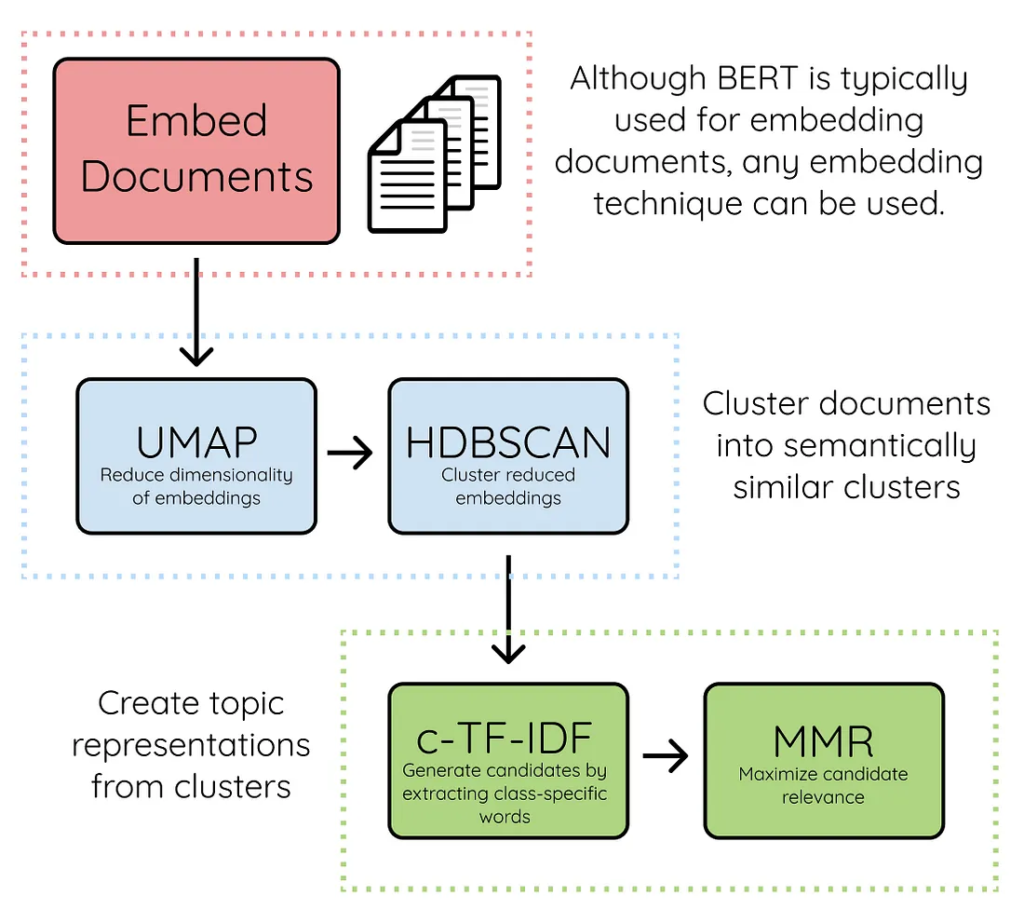
- Document Embedding: each document is converted into a high-dimensional vector using a transformer model. These embeddings are presented with the aim of capturing semantic meaning, not just word frequency.
- Dimensionality Reduction: High-dimensional embeddings are reduced to low dimensions using UMAP (Uniform Manifold Approximation and Projection) to preserve data structure and variation.
- Clustering: Documents are grouped and clustered using HDBSCAN (Hierarchical Density-Based Spatial Clustering of Applications with Noise), which is density-based and capable of handling clusters with varying densities and automatically detecting outliers.
- Vectorization: Text within clusters is converted into numerical features using CountVectorizer
- c-TF-IDF: All documents in a cluster are considered a ‘mega document’, then a specific TF-IDF score is calculated to find the most representative words for each topic.
- Representation Model: Topic representation can be further improved using KeyBERT, MMR, or even LLMs such as GPT to generate more meaningful topic labels.
3. Top2Vec Neural based (Embedding + Density Cluster)
Top2Vec works based on the assumption that many documents that are semantically similar indicate the existence of an underlying topic.
How Top2Vec works
Top2Vec works based on the assumption that many documents that are semantically similar indicate the existence of an underlying topic. The steps are:
- Joint Embedding: Creates document and word embeddings simultaneously using Doc2Vec, Universal Sentence Encoder, or other transformer models. Documents are placed close to similar documents and close to the words that most distinguish them.
- Dimensionality Reduction (UMAP): High-dimensional document vectors are reduced to facilitate searching for dense areas (dense areas)
- Dense Area Detection (HDBSCAN): The clustering algorithm finds dense areas of documents. Each dense area represents a topic, while points outside the area are considered outliers. .
- Topic Word Extraction: Words that “attract” documents to a particular dense area become keywords for that topic. Topic vectors are calculated as the centroids of document clusters.
4. TopikGPT
TopicGPT is a prompt-based topic modeling framework that utilizes the capabilities of LLMs such as GPT-3.5/GPT-4 to identify topics directly from text. Developed by Pham et al. and presented at NAACL 2024, TopicGPT generates topics in the form of natural language labels with descriptions, rather than just a list of words.
How TopikGPT works
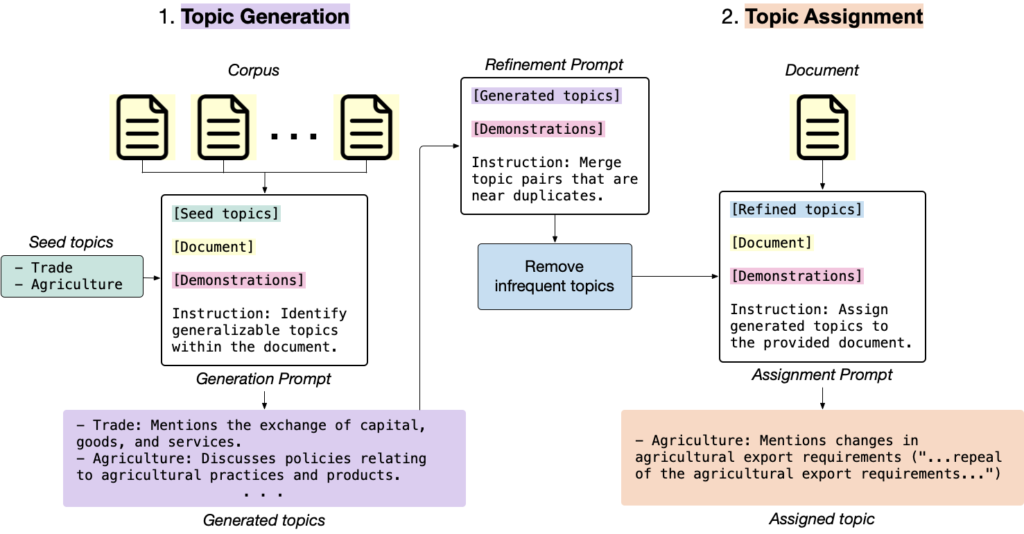
- Topic Generation: From a sample of documents, the LLM is asked to generate high-level (generalizable) topics along with their descriptions iteratively, by generating new topics while considering existing topics.
- Topic Refinement: The generated topics are filtered by first combining similar topics using embedding similarity, second removing rarely occurring topics, and finally optionally generating sub-topics (hierarchy).
- Topic Assignment: Each document is assigned to the appropriate topic by the LLM, accompanied by supporting quotes from the document. There is a self-correction mechanism to ensure that the assignment matches the list of valid topics.
Comparison of the Four Methods
The four methods have different strengths when applied to underground CTI data heavy with slang, code-switching, and obfuscation. The table below extends the standard technical comparison with two additional axes: CTI Suitability and Dark Web Performance, based on empirical findings from prior research applying these methods to cybercrime data.
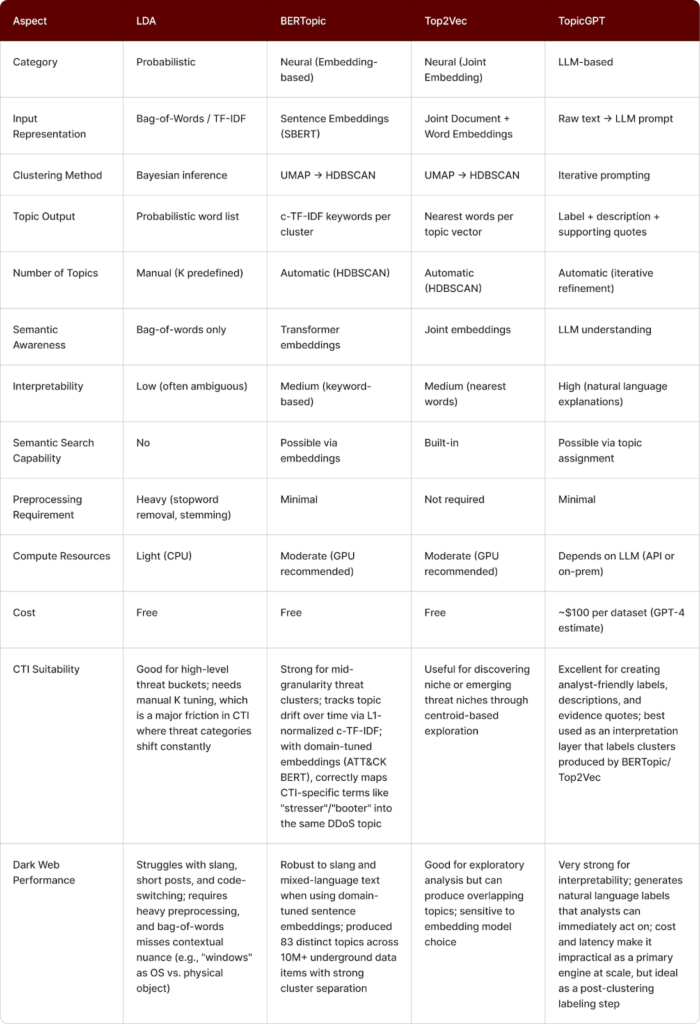
For slang-heavy dark web forum data, BERTopic with domain-tuned embeddings (e.g., ATT&CK BERT) outperforms LDA and produces better cluster coherence than Top2Vec. The recommended setup uses BERTopic for clustering and a TopicGPT-style LLM for labeling and evidence extraction. LDA remains a lightweight baseline, while Top2Vec is useful for early exploratory analysis.
However, model choice alone is insufficient at dark web scale. When processing millions of posts and messages, the challenge shifts from algorithm performance to architectural scalability and intelligence operationalization.
Therefore, Zentara Labs concludes that a layered pipeline integrating topic modeling, LLM-based interpretation, and structured consumption is required to convert raw underground data into tactical CTI decisions.I decisions.

- Discovery: Unstructured CTI data from forums, chats, and the darknet is processed using topic modeling methods such as LDA, BERTopic, or Top2Vec. The system clusters millions of messages into a number of topics that represent threat activities or trends.
- Interpretation: The LLM layer (e.g., TopicGPT) analyzes samples from each cluster to improve readability and accuracy. The model labels natural language, combines similar clusters, creates brief descriptions, and extracts evidence quotes from the original data.
- Consumption: Enriched topics are presented to the CTI/SOC team via dashboards, reports, or STIX (Structured Threat Information eXpression) exports. Analysts can monitor emerging threats, compare activity across platforms, and formulate threat hunting hypotheses and defensive actions.
Going forward, the modular architecture enables continuous model improvements, domain-tuned embeddings, and adaptive threat monitoring without disrupting operations.


