

We are shipping faster, but are we shipping safer? An LLM-based coding tool is an essential part of modern software development, particularly for teams that aim to ship features at an incredible speed. Every engineer must use these tools to stay competitive. Especially when GitHub data shows developers are 55% more productive when using Generative AI tools. However, generating more code strains security teams if they still have the same capacity to review it. This causes a massive backlog of unverified code. In this article, we will share how we stopped blindly trusting AI code and built a process to verify it.
We remember when tj-actions compromised in March 2025. It wasn’t a sophisticated server breach, but rather a supply chain flaw that looked standard. Any AI coding tool would have just recommended it without additional checking. This is the definition of “dangerous vibe coding”. This incident proves, according to the SusVibes benchmark, an 80% failure rate on security tests happened even though the AI code worked perfectly. We realized that focusing on quick code would lead to a significant security debt for our engineering team.
By analyzing our team process, we identified the core pain points of our team:
- “I just copied this from Copilot, and it works. Why is the security scan flagging it?”
- “I spent 20 minutes building the feature and 4 hours fixing the security findings.”
- “Did anyone check if this dependency assumes we’re using a secure version?”
We implemented a pattern called Recursive Criticism and Improvement (RCI). It’s a technique where you prompt the model to generate code, then immediately prompt it to critique its own output for vulnerabilities.
- Generation: “Generate a Flask route for user profile updates.”
- Critique: “Act as a senior security engineer. Critique that code for Mass Assignment vulnerabilities.”
- Refinement: “Based on your critique, rewrite the code to use a whitelist of fields.”
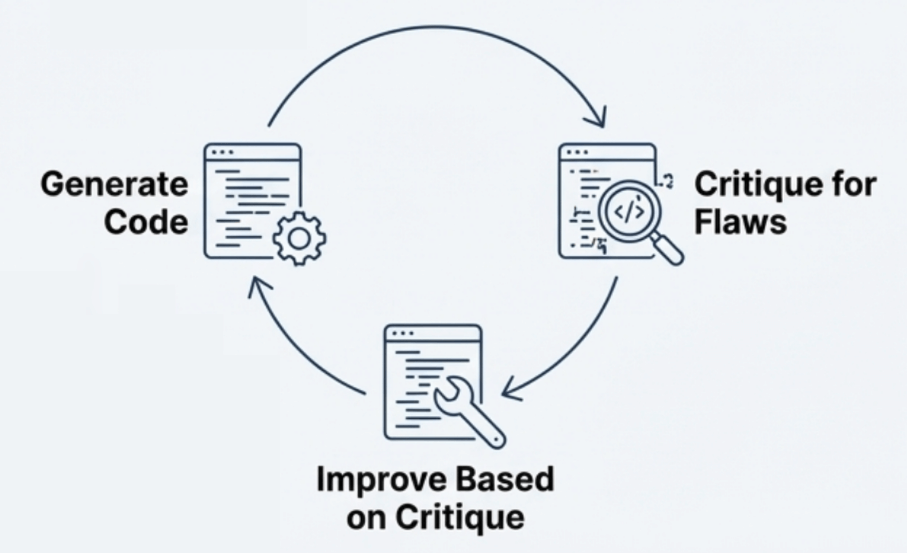
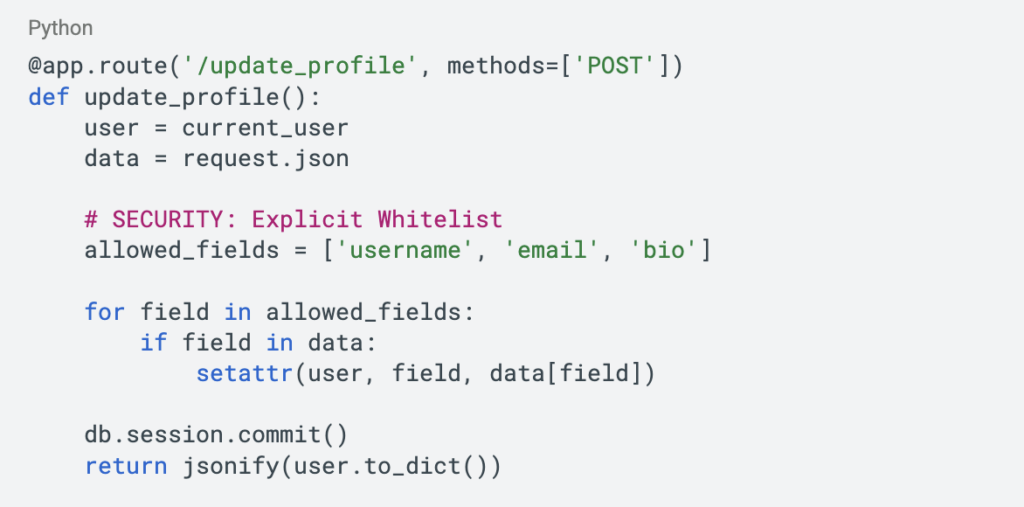
This simple loop collapses the design, security review, and development phases into a single step. It turned our prompts from simple questions into rigorous specifications. To understand the impact, look at what typically yields. It blindly accepts all input:

And here is the after-refinement, where the AI explicitly guards the data:
Even with better prompts, we can’t rely on luck. We needed a safety net that matched the speed of generation because a manual code review process simply cannot keep up with an AI that generates code in seconds. We adopted a Remediation-First approach using three layers:
- Static Analysis (SAST): Tools like Snyk Code AI or Semgrep work directly in the editor.
- Dynamic Analysis (DAST): We use tools like StackHawk to test the running application. This catches the bizarre, unexpected logic flows that only emerge at runtime.
- Automated Triage: We implemented automated triage tools that suggest deterministic fixes right in the pull request.
Our journey doesn’t end here. It continues with a new mindset, where we stop acting like consumers and start acting like commanders who guide AI and verify its output line by line to catch new threats. Because the code is ultimately only as safe as the engineer who approved it.

By implementing RCI prompts, automated remediation, and verification frameworks, we can keep the 55% productivity gain without inheriting the 80% security failure rate.


