
Artificial intelligence is now embedded in critical systems, from cybersecurity operations and healthcare diagnostics to legal analysis and enterprise decision-making. As adoption accelerates, one structural risk has become impossible to ignore: AI hallucinations.
Recent real-world incidents have shown that AI-generated misinformation can create legal, operational, and financial consequences. In one case, a chatbot fabricated a company policy, leading to legal liability.
The broader trend is concerning:
- AI security incidents are increasing year over year
- Nearly half of enterprise users admit to making important decisions based on inaccurate AI outputs
- Knowledge workers now spend hours each week verifying AI-generated content
The key insight: hallucination is not a temporary flaw. It is a structural property of probabilistic models. The responsibility, therefore, is not to “eliminate” hallucinations entirely, but to design systems that remain safe despite them.
What Is an AI Hallucination?
An AI hallucination occurs when a model generates plausible but factually incorrect or fabricated information.
Large language models do not “know” facts in the human sense. They predict the most statistically likely next word based on patterns learned from massive datasets. When confidence is misplaced, fabrication can occur.
Three Root Causes
1. Training Data Limitations
Models are trained on incomplete and sometimes biased datasets. When confronted with unfamiliar or ambiguous inputs, they often generate plausible answers rather than acknowledge uncertainty.
2. Incentive Misalignment
Most evaluation systems reward responsiveness. Models are incentivized to provide an answer instead of saying “I don’t know.”
3. Context & Reasoning Limits
Complex, multi-step reasoning increases the likelihood of fabricated references, incorrect assumptions, or logical breakdowns.
The Confidence Paradox
One of the most dangerous characteristics of hallucinations is tone. Models often sound most confident when they are wrong. In high-stakes environments, confident inaccuracy is more harmful than visible uncertainty.
Real-World Impact Across Industries
Hallucinations are not theoretical risks, they have already caused measurable harm.
Legal
There have been cases where AI-generated legal citations were fabricated and submitted in court filings. In regulated environments, this creates reputational and compliance risks.
Healthcare
In clinical contexts, AI systems have:
- Misclassified medical conditions
- Provided unsafe therapeutic advice
- Introduced fabricated content into medical documentation
In safety-critical domains, hallucination becomes a patient safety issue — not just an accuracy issue.
Cybersecurity & SOC Environments
Within security operations, hallucinations can:
- Generate phantom alerts
- Mislabel real threats as benign
- Produce flawed remediation guidance
A hallucinated “all clear” is significantly more dangerous than a hallucinated alert.
Software Supply Chain
Coding assistants sometimes suggest non-existent packages. Attackers have exploited this by publishing malicious packages using those hallucinated names — effectively weaponizing hallucination as an attack vector.
This represents a new paradigm: hallucination is now an exploitable attack surface.
Hallucination as a Cybersecurity Threat Vector
AI hallucinations introduce multiple attack surfaces:
- Passive Exploitation: The system hallucinates without external manipulation, causing internal damage.
- Active Exploitation: Attackers intentionally trigger hallucinations through adversarial prompts or prompt injection.
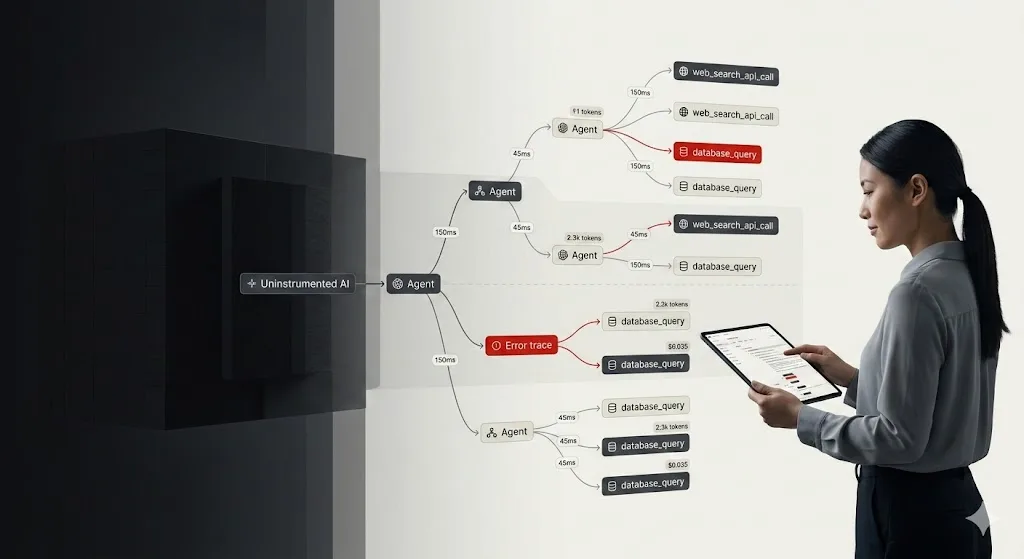
- Cascading Hallucinations: In multi-agent environments, one hallucinating system can contaminate downstream systems.
Additional risks include synthetic data poisoning and shadow AI systems deployed outside governance controls.
The risk is no longer theoretical. It is architectural.
Detection: You Can’t Mitigate What You Can’t Detect
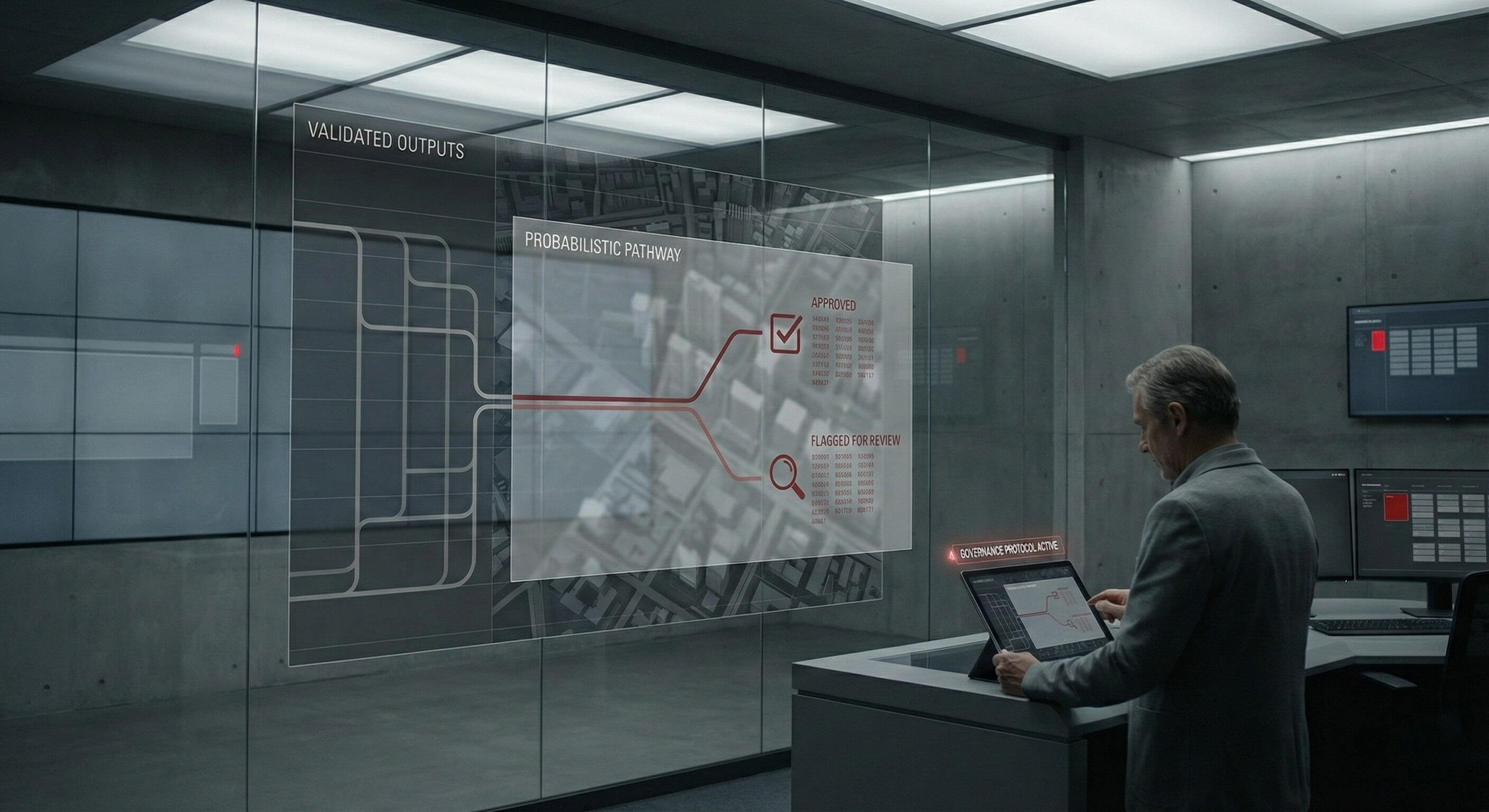
Effective detection requires structured validation mechanisms, such as:
- Self-consistency checking
- Retrieval-Augmented Generation (RAG) for grounding responses in verified data
- Confidence scoring with threshold controls
- Baseline comparisons against validated outputs
- Refusal training to enable safe “I don’t know” responses
- Domain-specific testing benchmarks
Even simple measures like re-asking the same question and comparing outputs can reduce hallucination risk. Detection must be engineered, not assumed.
Prevention & Mitigation: A Defence-in-Depth Approach
No single control eliminates hallucinations. The most effective strategy is layered defence.
1. Architecture-Level Controls
- Grounded generation (RAG)
- Domain-specific fine-tuning
- Constrained output formats
- Multi-model validation
2. Process-Level Controls
- Human-in-the-Loop oversight
- Tiered automation based on risk levels
- Structured prompt governance
3. Governance-Level Controls
- AI risk management frameworks
- Clear model documentation
- Auditability and compliance alignment
- Defined incident response for hallucination events
4. Continuous Monitoring
- Production monitoring for model drift
- Adversarial red-teaming
- User feedback and flagging mechanisms
When layered together, these controls dramatically reduce risk — but none are sufficient alone.
The Skills Shift
As AI integrates deeper into enterprise environments, hallucination mitigation is becoming a core cybersecurity competency.
Critical skill areas now include:
- Prompt engineering
- RAG architecture design
- AI red-teaming
- Understanding LLM limitations and failure modes
The intersection of AI safety, governance, and cybersecurity is rapidly emerging as one of the most important domains in modern security practice.
Final Takeaway
Hallucination rates will improve as models evolve, but they will never reach zero. Hallucination is an emergent property of probabilistic systems.
The question is no longer:
“Will my AI hallucinate?”
The real question is:
“Is my system designed to remain safe when it does?”